
Python 100 Days Day62 Web Crawler Using Python-2
23 Sep 2022 | beginner pythonauthor: jackfrued
用Python解析HTML頁面
在前面的課程中,我們講到了使用request三方庫獲取網絡資源,還介紹了一些前端的基礎知識。接下來,我們繼續探索如何解析 HTML 代碼,從頁面中提取出有用的信息。之前,我們嘗試過用正則表達式的捕獲組操作提取頁面內容,但是寫出一個正確的正則表達式也是一件讓人頭疼的事情。為了解決這個問題,我們得先深入的了解一下 HTML 頁面的結構,並在此基礎上研究另外的解析頁面的方法。
HTML 頁面的結構
我們在瀏覽器中打開任意一個網站,然後通過鼠標右鍵菜單,選擇“顯示網頁源代碼”菜單項,就可以看到網頁對應的 HTML 代碼。
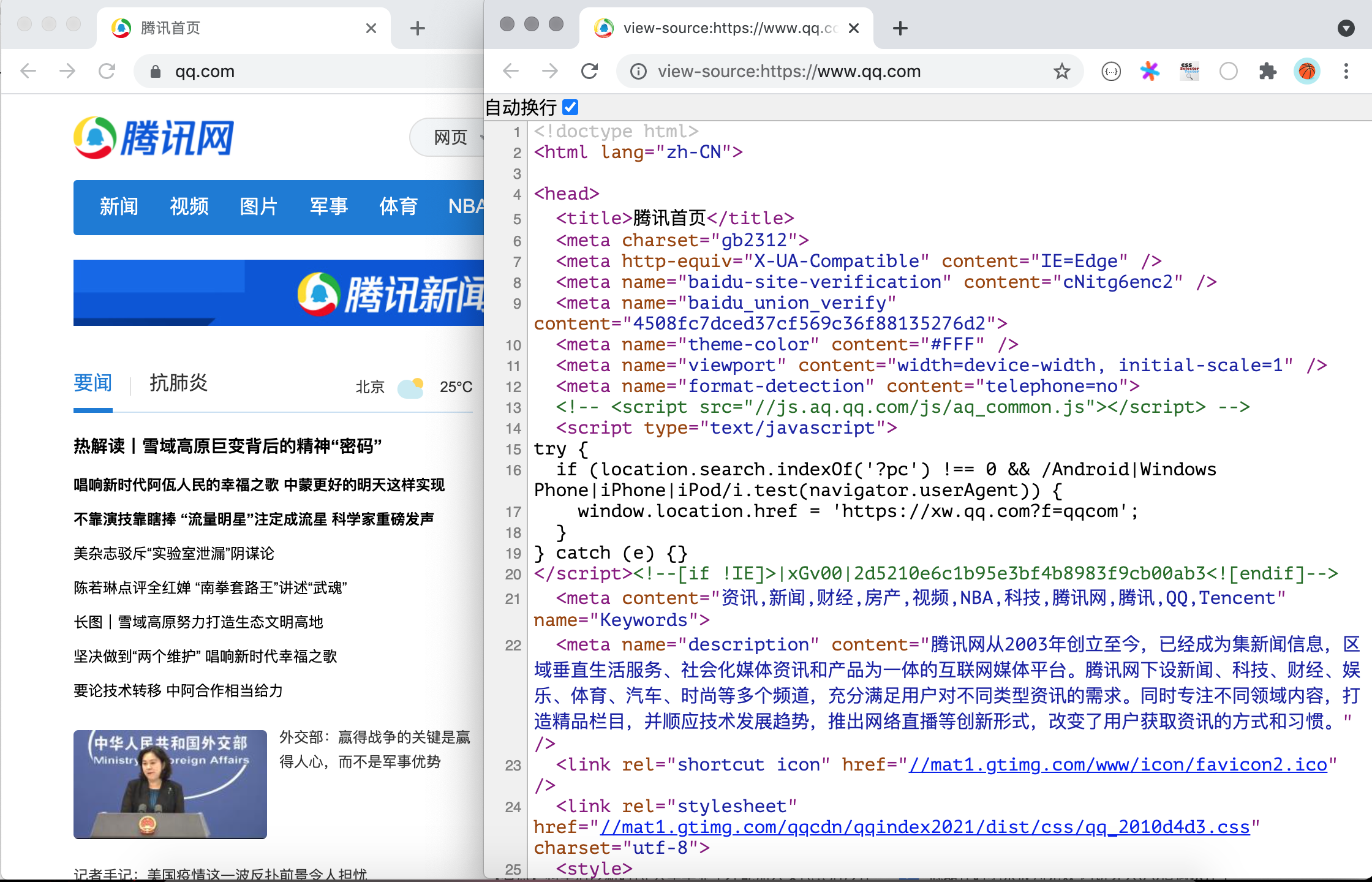
代碼的第1行是文檔類型聲明,第2行的<html>標簽是整個頁面根標簽的開始標簽,最後一行是根標簽的結束標簽</html>。<html>標簽下面有兩個子標簽<head>和<body>,放在<body>標簽下的內容會顯示在瀏覽器窗口中,這部分內容是網頁的主體;放在<head>標簽下的內容不會顯示在瀏覽器窗口中,但是卻包含了頁面重要的元信息,通常稱之為網頁的頭部。HTML 頁面大致的代碼結構如下所示。
<!doctype html>
<html>
<head>
<!-- 頁面的元信息,如字符編碼、標題、關鍵字、媒體查詢等 -->
</head>
<body>
<!-- 頁面的主體,顯示在瀏覽器窗口中的內容 -->
</body>
</html>
標簽、層疊樣式表(CSS)、JavaScript 是構成 HTML 頁面的三要素,其中標簽用來承載頁面要顯示的內容,CSS 負責對頁面的渲染,而 JavaScript 用來控制頁面的交互式行為。要實現 HTML 頁面的解析,可以使用 XPath 的語法,它原本是 XML 的一種查詢語法,可以根據 HTML 標簽的層次結構提取標簽中的內容或標簽屬性;此外,也可以使用 CSS 選擇器來定位頁面元素,就跟用 CSS 渲染頁面元素是同樣的道理。
XPath 解析
XPath 是在 XML(eXtensible Markup Language)文檔中查找信息的一種語法,XML 跟 HTML 類似也是一種用標簽承載數據的標簽語言,不同之處在於 XML 的標簽是可擴展的,可以自定義的,而且 XML 對語法有更嚴格的要求。XPath 使用路徑表達式來選取 XML 文檔中的節點或者節點集,這里所說的節點包括元素、屬性、文本、命名空間、處理指令、注釋、根節點等。下面我們通過一個例子來說明如何使用 XPath 對頁面進行解析。
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="zh">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
對於上面的 XML 文件,我們可以用如下所示的 XPath 語法獲取文檔中的節點。
| 路徑表達式 | 結果 |
|---|---|
/bookstore |
選取根元素 bookstore。注意:假如路徑起始於正斜杠( / ),則此路徑始終代表到某元素的絕對路徑! |
//book |
選取所有 book 子元素,而不管它們在文檔中的位置。 |
//@lang |
選取名為 lang 的所有屬性。 |
/bookstore/book[1] |
選取屬於 bookstore 子元素的第一個 book 元素。 |
/bookstore/book[last()] |
選取屬於 bookstore 子元素的最後一個 book 元素。 |
/bookstore/book[last()-1] |
選取屬於 bookstore 子元素的倒數第二個 book 元素。 |
/bookstore/book[position()<3] |
選取最前面的兩個屬於 bookstore 元素的子元素的 book 元素。 |
//title[@lang] |
選取所有擁有名為 lang 的屬性的 title 元素。 |
//title[@lang='eng'] |
選取所有 title 元素,且這些元素擁有值為 eng 的 lang 屬性。 |
/bookstore/book[price>35.00] |
選取 bookstore 元素的所有 book 元素,且其中的 price 元素的值須大於 35.00。 |
/bookstore/book[price>35.00]/title |
選取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值須大於 35.00。 |
XPath還支持通配符用法,如下所示。
| 路徑表達式 | 結果 |
|---|---|
/bookstore/* |
選取 bookstore 元素的所有子元素。 |
//* |
選取文檔中的所有元素。 |
//title[@*] |
選取所有帶有屬性的 title 元素。 |
如果要選取多個節點,可以使用如下所示的方法。
| 路徑表達式 | 結果 |
|---|---|
//book/title \| //book/price |
選取 book 元素的所有 title 和 price 元素。 |
//title \| //price |
選取文檔中的所有 title 和 price 元素。 |
/bookstore/book/title \| //price |
選取屬於 bookstore 元素的 book 元素的所有 title 元素,以及文檔中所有的 price 元素。 |
說明:上面的例子來自於“菜鳥教程”網站上的 XPath 教程,有興趣的讀者可以自行閱讀原文。
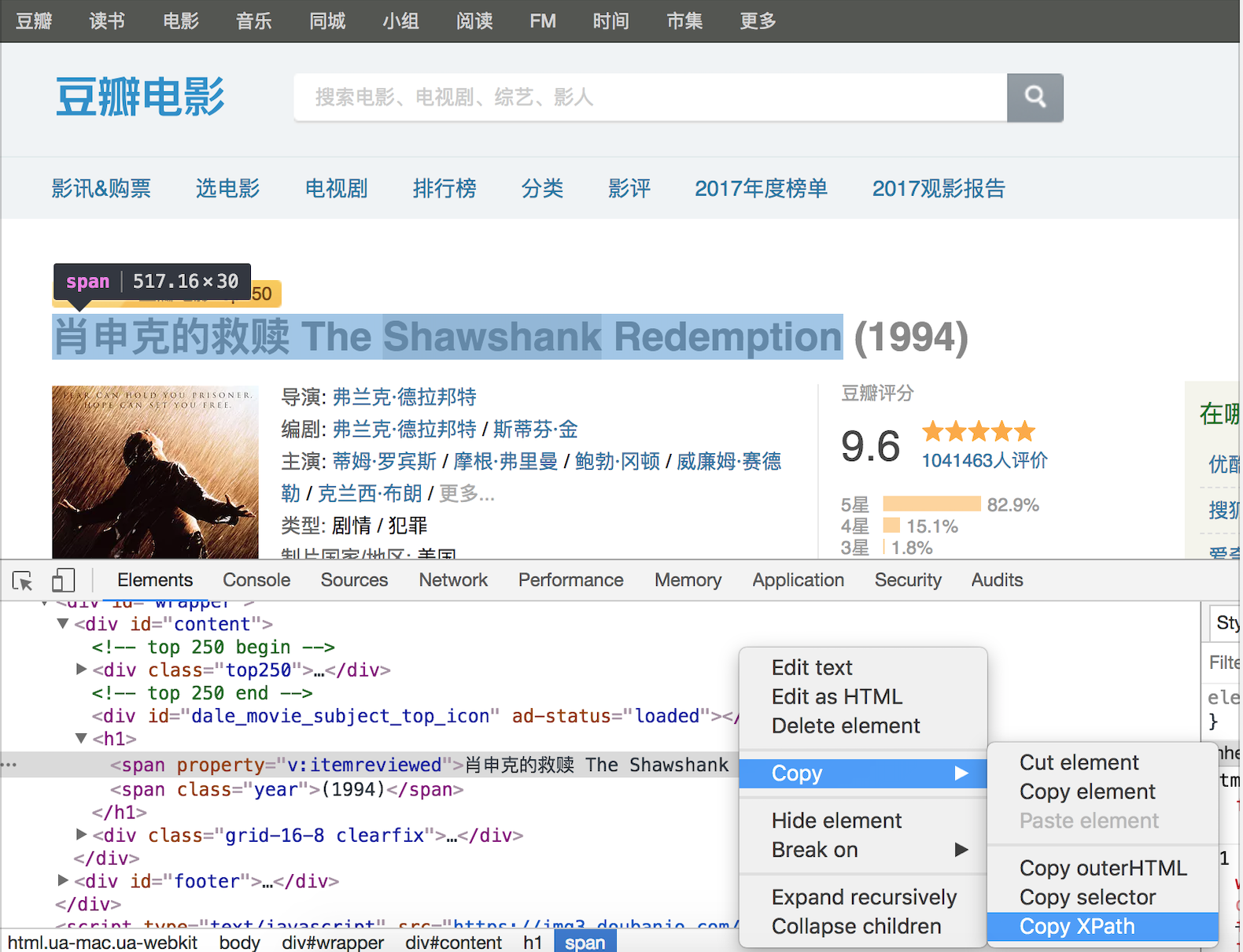
當然,如果不理解或不熟悉 XPath 語法,可以在瀏覽器的開發者工具中按照如下所示的方法查看元素的 XPath 語法,下圖是在 Chrome 瀏覽器的開發者工具中查看豆瓣網電影詳情信息中影片標題的 XPath 語法。
實現 XPath 解析需要三方庫lxml 的支持,可以使用下面的命令安裝lxml。
pip install lxml
下面我們用 XPath 解析方式改寫之前獲取豆瓣電影 Top250的代碼,如下所示。
from lxml import etree
import requests
for page in range(1, 11):
resp = requests.get(
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
headers={'User-Agent': 'BaiduSpider'}
)
tree = etree.HTML(resp.text)
# 通過XPath語法從頁面中提取電影標題
title_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]')
# 通過XPath語法從頁面中提取電影評分
rank_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[2]')
for title_span, rank_span in zip(title_spans, rank_spans):
print(title_span.text, rank_span.text)
CSS 選擇器解析
對於熟悉 CSS 選擇器和 JavaScript 的開發者來說,通過 CSS 選擇器獲取頁面元素可能是更為簡單的選擇,因為瀏覽器中運行的 JavaScript 本身就可以document對象的querySelector()和querySelectorAll()方法基於 CSS 選擇器獲取頁面元素。在 Python 中,我們可以利用三方庫beautifulsoup4或pyquery來做同樣的事情。Beautiful Soup 可以用來解析 HTML 和 XML 文檔,修覆含有未閉合標簽等錯誤的文檔,通過為待解析的頁面在內存中創建一棵樹結構,實現對從頁面中提取數據操作的封裝。可以用下面的命令來安裝 Beautiful Soup。
pip install beautifulsoup4
下面是使用bs4改寫的獲取豆瓣電影Top250電影名稱的代碼。
import bs4
import requests
for page in range(1, 11):
resp = requests.get(
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
headers={'User-Agent': 'BaiduSpider'}
)
# 創建BeautifulSoup對象
soup = bs4.BeautifulSoup(resp.text, 'lxml')
# 通過CSS選擇器從頁面中提取包含電影標題的span標簽
title_spans = soup.select('div.info > div.hd > a > span:nth-child(1)')
# 通過CSS選擇器從頁面中提取包含電影評分的span標簽
rank_spans = soup.select('div.info > div.bd > div > span.rating_num')
for title_span, rank_span in zip(title_spans, rank_spans):
print(title_span.text, rank_span.text)
關於 BeautifulSoup 更多的知識,可以參考它的官方文檔。
簡單的總結
下面我們對三種解析方式做一個簡單比較。
| 解析方式 | 對應的模塊 | 速度 | 使用難度 |
|---|---|---|---|
| 正則表達式解析 | re |
快 | 困難 |
| XPath 解析 | lxml |
快 | 一般 |
| CSS 選擇器解析 | bs4或pyquery |
不確定 | 簡單 |
Comments