
Python 100 Days Day51 Cache
22 Sep 2022 | beginner pythonauthor: jackfrued
使用緩存
通常情況下,Web應用的性能瓶頸都會出現在關系型數據庫上,當並發訪問量較大時,如果所有的請求都需要通過關系型數據庫完成數據持久化操作,那麽數據庫一定會不堪重負。優化Web應用性能最為重要的一點就是使用緩存,把那些數據體量不大但訪問頻率非常高的數據提前加載到緩存服務器中,這又是典型的空間換時間的方法。通常緩存服務器都是直接將數據置於內存中而且使用了非常高效的數據存取策略(哈希存儲、鍵值對方式等),在讀寫性能上遠遠優於關系型數據庫的,因此我們可以讓Web應用接入緩存服務器來優化其性能,其中一個非常好的選擇就是使用Redis。
Web應用的緩存架構大致如下圖所示。
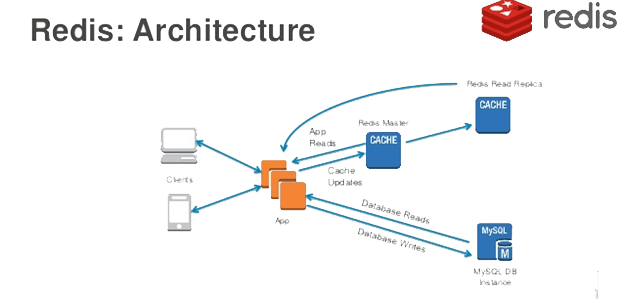
Django項目接入Redis
在此前的課程中,我們介紹過Redis的安裝和使用,此處不再進行贅述。如果需要在Django項目中接入Redis,可以使用三方庫django-redis,這個三方庫又依賴了一個名為redis 的三方庫,它封裝了對Redis的各種操作。
安裝django-redis。
pip install django-redis
修改Django配置文件中關於緩存的配置。
CACHES = {
'default': {
# 指定通過django-redis接入Redis服務
'BACKEND': 'django_redis.cache.RedisCache',
# Redis服務器的URL
'LOCATION': ['redis://1.2.3.4:6379/0', ],
# Redis中鍵的前綴(解決命名沖突)
'KEY_PREFIX': 'vote',
# 其他的配置選項
'OPTIONS': {
'CLIENT_CLASS': 'django_redis.client.DefaultClient',
# 連接池(預置若幹備用的Redis連接)參數
'CONNECTION_POOL_KWARGS': {
# 最大連接數
'max_connections': 512,
},
# 連接Redis的用戶口令
'PASSWORD': 'foobared',
}
},
}
至此,我們的Django項目已經可以接入Redis,接下來我們修改項目代碼,用Redis為之寫的獲取學科數據的接口提供緩存服務。
為視圖提供緩存服務
聲明式緩存
所謂聲明式緩存是指不修改原來的代碼,通過Python中的裝飾器(代理)為原有的代碼增加緩存功能。對於FBV,代碼如下所示。
from django.views.decorators.cache import cache_page
@api_view(('GET', ))
@cache_page(timeout=86400, cache='default')
def show_subjects(request):
"""獲取學科數據"""
queryset = Subject.objects.all()
data = SubjectSerializer(queryset, many=True).data
return Response({'code': 20000, 'subjects': data})
上面的代碼通過Django封裝的cache_page裝飾器緩存了視圖函數的返回值(響應對象),cache_page的本意是緩存視圖函數渲染的頁面,對於返回JSON數據的視圖函數,相當於是緩存了JSON數據。在使用cache_page裝飾器時,可以傳入timeout參數來指定緩存過期時間,還可以使用cache參數來指定需要使用哪一組緩存服務來緩存數據。Django項目允許在配置文件中配置多組緩存服務,上面的cache='default'指定了使用默認的緩存服務(因為之前的配置文件中我們也只配置了名為default的緩存服務)。視圖函數的返回值會被序列化成字節串放到Redis中(Redis中的str類型可以接收字節串),緩存數據的序列化和反序列化也不需要我們自己處理,因為cache_page裝飾器會調用django-redis庫中的RedisCache來對接Redis,該類使用了DefaultClient來連接Redis並使用了pickle序列化,django_redis.serializers.pickle.PickleSerializer是默認的序列化類。
如果緩存中沒有學科的數據,那麽通過接口訪問學科數據時,我們的視圖函數會通過執行Subject.objects.all()向數據庫發出SQL語句來獲得數據,視圖函數的返回值會被緩存,因此下次請求該視圖函數如果緩存沒有過期,可以直接從緩存中獲取視圖函數的返回值,無需再次查詢數據庫。如果想了解緩存的使用情況,可以配置數據庫日志或者使用Django-Debug-Toolbar來查看,第一次訪問學科數據接口時會看到查詢學科數據的SQL語句,再次獲取學科數據時,不會再向數據庫發出SQL語句,因為可以直接從緩存中獲取數據。
對於CBV,可以利用Django中名為method_decorator的裝飾器將cache_page這個裝飾函數的裝飾器放到類中的方法上,效果跟上面的代碼是一樣的。需要提醒大家注意的是,cache_page裝飾器不能直接放在類上,因為它是裝飾函數的裝飾器,所以Django框架才提供了method_decorator來解決這個問題,很顯然,method_decorator是一個裝飾類的裝飾器。
from django.utils.decorators import method_decorator
from django.views.decorators.cache import cache_page
@method_decorator(decorator=cache_page(timeout=86400, cache='default'), name='get')
class SubjectView(ListAPIView):
"""獲取學科數據的視圖類"""
queryset = Subject.objects.all()
serializer_class = SubjectSerializer
編程式緩存
所謂編程式緩存是指通過自己編寫的代碼來使用緩存服務,這種方式雖然代碼量會稍微大一些,但是相較於聲明式緩存,它對緩存的操作和使用更加靈活,在實際開發中使用得更多。下面的代碼去掉了之前使用的cache_page裝飾器,通過django-redis提供的get_redis_connection函數直接獲取Redis連接來操作Redis。
def show_subjects(request):
"""獲取學科數據"""
redis_cli = get_redis_connection()
# 先嘗試從緩存中獲取學科數據
data = redis_cli.get('vote:polls:subjects')
if data:
# 如果獲取到學科數據就進行反序列化操作
data = json.loads(data)
else:
# 如果緩存中沒有獲取到學科數據就查詢數據庫
queryset = Subject.objects.all()
data = SubjectSerializer(queryset, many=True).data
# 將查到的學科數據序列化後放到緩存中
redis_cli.set('vote:polls:subjects', json.dumps(data), ex=86400)
return Response({'code': 20000, 'subjects': data})
需要說明的是,Django框架提供了cache和caches兩個現成的變量來支持緩存操作,前者訪問的是默認的緩存(名為default的緩存),後者可以通過索引運算獲取指定的緩存服務(例如:caches['default'])。向cache對象發送get和set消息就可以實現對緩存的讀和寫操作,但是這種方式能做的操作有限,不如上面代碼中使用的方式靈活。還有一個值得注意的地方,由於可以通過get_redis_connection函數獲得的Redis連接對象向Redis發起各種操作,包括FLUSHDB、SHUTDOWN等危險的操作,所以在實際商業項目開發中,一般都會對django-redis再做一次封裝,例如封裝一個工具類,其中只提供了項目需要用到的緩存操作的方法,從而避免了直接使用get_redis_connection的潛在風險。當然,自己封裝對緩存的操作還可以使用“Read Through”和“Write Through”的方式實現對緩存的更新,這個在下面會介紹到。
緩存相關問題
緩存數據的更新
在使用緩存時,一個必須搞清楚的問題就是,當數據改變時,如何更新緩存中的數據。通常更新緩存有如下幾種套路,分別是:
- Cache Aside Pattern
- Read/Write Through Pattern
- Write Behind Caching Pattern
第1種方式的具體做法就是,當數據更新時,先更新數據庫,再刪除緩存。注意,不能夠使用先更新數據庫再更新緩存的方式,也不能夠使用先刪除緩存再更新數據庫的方式,大家可以自己想一想為什麽(考慮一下有並發的讀操作和寫操作的場景)。當然,先更新數據庫再刪除緩存的做法在理論上也存在風險,但是發生問題的概率是極低的,所以不少的項目都使用了這種方式。
第1種方式相當於編寫業務代碼的開發者要自己負責對兩套存儲系統(緩存和關系型數據庫)的操作,代碼寫起來非常的繁瑣。第2種方式的主旨是將後端的存儲系統變成一套代碼,對緩存的維護封裝在這套代碼中。其中,Read Through指在查詢操作中更新緩存,也就是說,當緩存失效的時候,由緩存服務自己負責對數據的加載,從而對應用方是透明的;而Write Through是指在更新數據時,如果沒有命中緩存,直接更新數據庫,然後返回。如果命中了緩存,則更新緩存,然後再由緩存服務自己更新數據庫(同步更新)。剛才我們說過,如果自己對項目中的Redis操作再做一次封裝,就可以實現“Read Through”和“Write Through”模式,這樣做雖然會增加工作量,但無疑是一件“一勞永逸”且“功在千秋”的事情。
第3種方式是在更新數據的時候,只更新緩存,不更新數據庫,而緩存服務這邊會異步的批量更新數據庫。這種做法會大幅度提升性能,但代價是犧牲數據的強一致性。第3種方式的實現邏輯比較覆雜,因為他需要追蹤有哪數據是被更新了的,然後再批量的刷新到持久層上。
緩存穿透
緩存是為了緩解數據庫壓力而添加的一個中間層,如果惡意的訪問者頻繁的訪問緩存中沒有的數據,那麽緩存就失去了存在的意義,瞬間所有請求的壓力都落在了數據庫上,這樣會導致數據庫承載著巨大的壓力甚至連接異常,類似於分布式拒絕服務攻擊(DDoS)的做法。解決緩存穿透的一個辦法是約定如果查詢返回為空值,把這個空值也緩存起來,但是需要為這個空值的緩存設置一個較短的超時時間,畢竟緩存這樣的值就是對緩存空間的浪費。另一個解決緩存穿透的辦法是使用布隆過濾器,具體的做法大家可以自行了解。
緩存擊穿
在實際的項目中,可能存在某個緩存的key某個時間點過期,但恰好在這個時間點對有對該key的大量的並發請求過來,這些請求沒有從緩存中找到key對應的數據,就會直接從數據庫中獲取數據並寫回到緩存,這個時候大並發的請求可能會瞬間把數據庫壓垮,這種現象稱為緩存擊穿。比較常見的解決緩存擊穿的辦法是使用互斥鎖,簡單的說就是在緩存失效的時候,不是立即去數據庫加載數據,而是先設置互斥鎖(例如:Redis中的setnx),只有設置互斥鎖的操作成功的請求,才能執行查詢從數據庫中加載數據並寫入緩存,其他設置互斥鎖失敗的請求,可以先執行一個短暫的休眠,然後嘗試重新從緩存中獲取數據,如果緩存還沒有數據,則重覆剛才的設置互斥鎖的操作,大致的參考代碼如下所示。
data = redis_cli.get(key)
while not data:
if redis_cli.setnx('mutex', 'x'):
redis.expire('mutex', timeout)
data = db.query(...)
redis.set(key, data)
redis.delete('mutex')
else:
time.sleep(0.1)
data = redis_cli.get(key)
緩存雪崩
緩存雪崩是指在將數據放入緩存時采用了相同的過期時間,這樣就導致緩存在某一時刻同時失效,請求全部轉發到數據庫,導致數據庫瞬時壓力過大而崩潰。解決緩存雪崩問題的方法也比較簡單,可以在既定的緩存過期時間上加一個隨機時間,這樣可以從一定程度上避免不同的key在同一時間集體失效。還有一種辦法就是使用多級緩存,每一級緩存的過期時間都不一樣,這樣的話即便某個級別的緩存集體失效,但是其他級別的緩存還能夠提供數據,避免所有的請求都落到數據庫上。
Comments